查证主键设置UUID导致insert慢的问题
2024-01-30
我们这边有个登录接口,在压测下表现不是很好,压测结果有时高有时低。听压测的同事反馈,有个奇怪的现象:偶尔慢一会,然后过一会又会上去,压测的结果就好像画门一样,高一段,然后低一段,最高可以去到300/s,最低去到100/s。
基于这个现象,开始排查具体的卡顿点,大概率猜测是数据库相关操作导致了这个登录接口性能不佳。先登录MySQL,看下慢查询日志。
先确定有打开慢查询日志和日志存储路径。
mysql> show variables like '%slow_query_log%';
+---------------------+-------------------------+
| slow_query_log | ON |
| slow_query_log_file | /var/log/mysql/slow.log |
+---------------------+-------------------------+
2 rows in set (0.00 sec)
查看慢查询日志触发条件,我们这里是2秒触发记录慢查询日志。
mysql> show variables like 'long_query_time';
+-----------------+----------+
| long_query_time | 2.000000 |
+-----------------+----------+
1 row in set (0.00 sec)
查看慢查询日志后发现都是这么一条语句
# Time: 2024-01-18T12:27:16.639214Z
# User@Host: root[root] @ [10.10.56.12] Id: 1938599
# Query_time: 2.344242 Lock_time: 0.000001 Rows_sent: 0 Rows_examined: 0
SET timestamp=1705580834;
insert into t_ci_token
( id,user,create_time
,activate_time)
values ('MTEwOQ==-mr4pgGiUkEBaFVlNjRcJUdwJFbPPaVQ6SktmeErcqYEKy1ns9LAUT1bFxMb4',1109,'2024-01-18 20:27:14.288'
,'2024-01-18 20:27:14.288');
这样一条看似平平无奇的insert语句居然花费了2秒多。我查看了当时MySQL机器的监控,当时CPU和内存尚未用完,所以排除了这个慢查询出现并非是资源不足的原因。
在印象中MySQL的插入性能还是很强悍的,一般不需要特别SQL调优,看了下当前数据量(100w)也并不是很大的数据,所以插入数据花费了2秒十分离谱。
此时意识到这个可能是因为主键设计不当导致的,所以特意去看了其表的结构:
.png)
这个表id作为主键是字符串类型,对应的就是一个随机生成的token。这里表设计就有问题了,token应该由uuid生成,是无序的字符串,当无序字符串作为主键插入时,将会是无序随机插入,这样插入性能会很差。而我们一般采取自增主键插入则是顺序插入,插入性能稳定且高效,在数据量大的环境下插入仍能保持高效的插入性能。
后面问了下登录接口的开发者,这么设计这个token表有什么考虑,回答说是之前的外包出去设计的表,我建议说还是改回自增主键插入,不然这里之后就是一个坑。
这里额外再补充解释两个问题:
- 为什么随机插入会慢
- 为什么不建议这么做uuid作为主键
这里先介绍下uuid的构成部分。
uuid 有5个版本,用得最广的是v1和v4,这里讲解下两者区别。
uuid v1: 版本1 uuid是最常见的,它将MAC地址和时间戳组合在一起以产生足够的唯一性。uuid v1由以下几个部分组成:时间戳+随机数+mac地址。
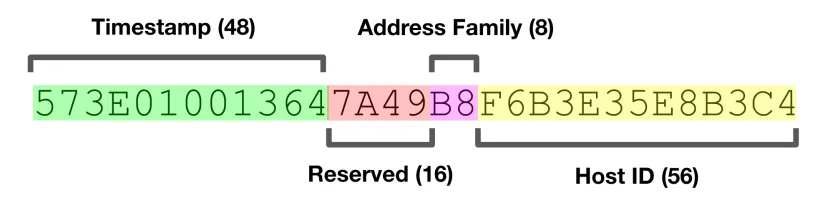
uuid v4: 仅仅是128位随机数据,通过一些位操作来识别uuid版本和变体。所以uuid v4是有可能重复出现的,但是这种概率非常小。如果不是严格要求,可以使用它代替uuid v1。

通过上面介绍,我们知道uuid v1和v4因为有随机序列的缘故,所以每个uuid都必然无序。如果我们数据库的主键采取的是uuid v1或者v4,那就意味着主键是无序的字符串,那随机插入时为什么会更耗时呢?
我们需要从MySQL底层引擎的数据组织方法来说明这个问题。我们在使用innodb作为引擎的情况下,在Innodb下主键索引是聚簇索引。以下是聚簇索引结构的示意图,主键索引树的叶子节点存储具体数据(叶子节点有序),而辅助索引树仅存储索引,查具体数据时需要回表查主键索引树。
.png)
随机插入的情况,比如使用了uuid聚簇索引的表插入数据。因为新插入的值是随机,可能比上一个插入的主键值大,也可能小,所以InnoDB无法简单的总是把新的记录插入到索引的最后,也就是说插入的位置很有可能是在现有数据的中间。这往往会导致性能恶化。
这种随机插入方式可能会有以下缺点:
- 写入的目标页可能不在内存缓存区,那么插入记录的时候需要先从磁盘读取目标页到内存中。这会导致大量的随机IO。如果是顺序插入,由于是插入到上一个记录的后面,则大多数情况下(不需要开辟新页的情况)磁盘页是已经加载到内存了的。
- 因为写入是乱序的,InnoDB可能需要不断的的做页分裂操作,以便为新的行分配空间。而页分裂会导致移动大量的数据,对于乱序插入一次分裂至少要修改2个页而不是1个页(假设插入位置非尾页)。而对于顺序插入,那么即使是发生页分裂,插入位置是固定在最后一个页上,即新增一个页或者在最后一个页上修改,只修改了1个页面,在耗时上顺序插入会更少。另外由于频繁的分页,页面会变得稀疏并被不规则的填充,最后会导致数据碎片。