fftw非线程安全的一些解决思路
2024-05-08
实际工程中要用到快速傅里叶变换fft,我们一般会使用知名的fft库FFTW,因为FFTW在计算性能和稳定性上都有很大的优势,以下是fft库的benchmark:
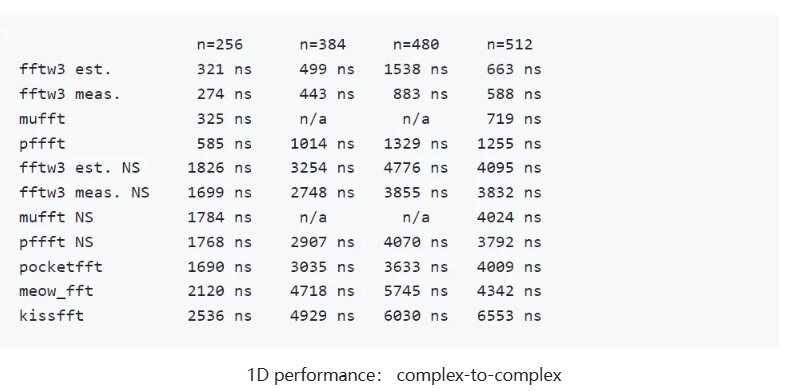
从性能测试的结果来看,fftw3这个库性能非常好,遥遥领先其他fft库,所以也是最受欢迎的fft库。但是fftw有个很致命的缺点:非线程安全。
fftw为了加速性能,在算法内部大量使用了全局变量来计算,所以能维持最佳的计算性能。但是一旦在多线程环境调用fftw的库函数,那么就会coredump。我最近在我的多线程Server里处理并发fft请求时,程序会异常coredump,最后定位到是fftw这个非线程安全的问题。
针对fftw的非线程安全问题,fftw官网是这么解答的:
https://www.fftw.org/fftw3_doc/Thread-safety.html
总的来说就是:
- fftw只有fftw_execute是线程安全的,其他的函数比如fftw_malloc、fftw_plan_dft_r2c_1d、fftw_free等函数都是非线程安全。即只有执行paln时是线程安全,至于开辟回收内存的操作都非线程安全。
- fftw只用于单线程场景,如果万不得已要在多线程场景下使用,那就只能加锁,但是加锁后fftw的性能将会急速下降。
- fftw有些plugins可以帮忙加锁来保证线程安全,比如调用fftw_make_planner_thread_safe函数,但本质上就是加锁,这也会严重影响计算性能。
方案一:fftw加锁
暴力加锁的方案,性能都很低,原本10ms计算好的fft,可能要去到800ms。如果真的图方便要解决程序在fftw多线程下coredump的问题,而且也不在乎性能的话,可以直接加锁。代码大概是就是在调用FFTW库函数时直接加锁,计算完就释放锁。
m_mutex.lock()
fftw_plan p;
double *in1_c =(double*) fftw_malloc(sizeof(double)* NFFT);
fftw_complex *out1_c = (fftw_complex*)fftw_malloc(sizeof(fftw_complex)* NFFT);
p = fftw_plan_dft_r2c_1d(NFFT, in1_c, out1_c, FFTW_ESTIMATE);//
···
fftw_execute(p);
···
fftw_free(in1_c); fftw_free(out1_c);
fftw_destroy_plan(p);
m_mutex.unlock()
方案二:C++调用python fft库
因为加锁的方案实在太慢了,那么此时开始寻找其他思路去解决这个问题。一个思路就是,我能不能通过调用python 相关的fft库来解决这个fft计算的问题?python中有很多fft库,这些库底层都是C写的也经过了一系列优化,性能应该不错。这里我使用了scipy.fftpack库做fft,Python调用方式很简单:
import scipy.fftpack as fpk
out1_c = fpk.fft(in1_c)
因为我的程序是C++编写,这里就存在C++调用python的方式,我这边采用pybind来做这个胶水层完成这项任务。
std::vector<double> fft(std::vector<double> input)
{
py::gil_scoped_acquire acquire;
py::list input_pylist = py::cast(input);
//用import函数导入python模块
auto module=py::module::import("pycall");
py::object out = module.attr("fft")(input_pylist);
auto v =out.cast<py::array_t<double>>();
auto vec = ndarray_to_vector(v);
return vec;
}
这个方案测试下来发现,总体性能较方案1提升较大,但也限于Python的GIL,性能也没有达到预期。
方案三:使用其他fft库替换
因为性能的问题我需要寻找更合适的fft方案,因此开始在调研业界还有哪些性能还不错库。fft库的调研结果如下:
| 算法库 | 计算速度 | 线程安全 | license | 支持的精度 | 使用者数量 | header only |
|---|---|---|---|---|---|---|
| FFTW | 非常快 | 否 | GPL or $ | 单+双 | 非常多(2.5k star) | 否 |
| ffts | 很快 | 否 | MIT | 单+双 | 多(516 star) | 否 |
| kfr | 非常快 | 是 | GPL or $ | 单+双 | 很多(1.5k star) | 否 |
| pffft | 很快 | 是 | BSD-like | 单 | 一般(219 star) | 是 |
| muFFT | 很快 | 是 | MIT | 单 | 少(142 star) | 否 |
| KissFFT | 一般 | 是 | 3-BSD | 单+双 | 很多(1.3k star) | 否 |
| meow_fft | 一般 | 是 | 0-BSD | 单 | 少(102 star) | 是 |
这里总结一下选择的思路:
- 如果你需要线程安全且使用者比较多(相对可靠)的fft库,那么可以在ktr、KissFFT中来选,在此基础上,如果还想追求性能那么kfr优先,但是注意kfr商用是要给钱的,如果能接受KissFFT一般的计算速度,那么就选KissFFT,毕竟是BSD证书。
- 如果没有线程安全的需求,那么直接优先FFTW。如果要商用又不想给钱,那就上ffts,或者受众更多但更慢的KissFFT。
根据我的项目实际情况,我需要线程安全+相对可靠+免费的FFT库,最后我选择了KissFFT作为我的底层算法库,改造了我一些算法函数。大概的写法如下:
kiss_fft_cpx rin[NFFT];
kiss_fft_cpx sout[NFFT];
kiss_fft_cfg kiss_fft_state;
kiss_fft_scalar zero;
kiss_fft_state = kiss_fft_alloc(NFFT,0,0,0);
···
kiss_fft(kiss_fft_state,rin,sout);
···
kiss_fft_free(kiss_fft_state);
改造后函数计算速度相对于前两个方案有巨大提升,已经能满足项目的性能要求,因此备选方案pffft和muFFT就没有再尝试了,看测评结果,pffft和muFFT计算速度大概是KissFFT的5倍左右,如果后续有更高的性能要求,可以试试这两个线程安全的FFT库。