大文件分块上传和断点续传
2023-12-06
方案介绍
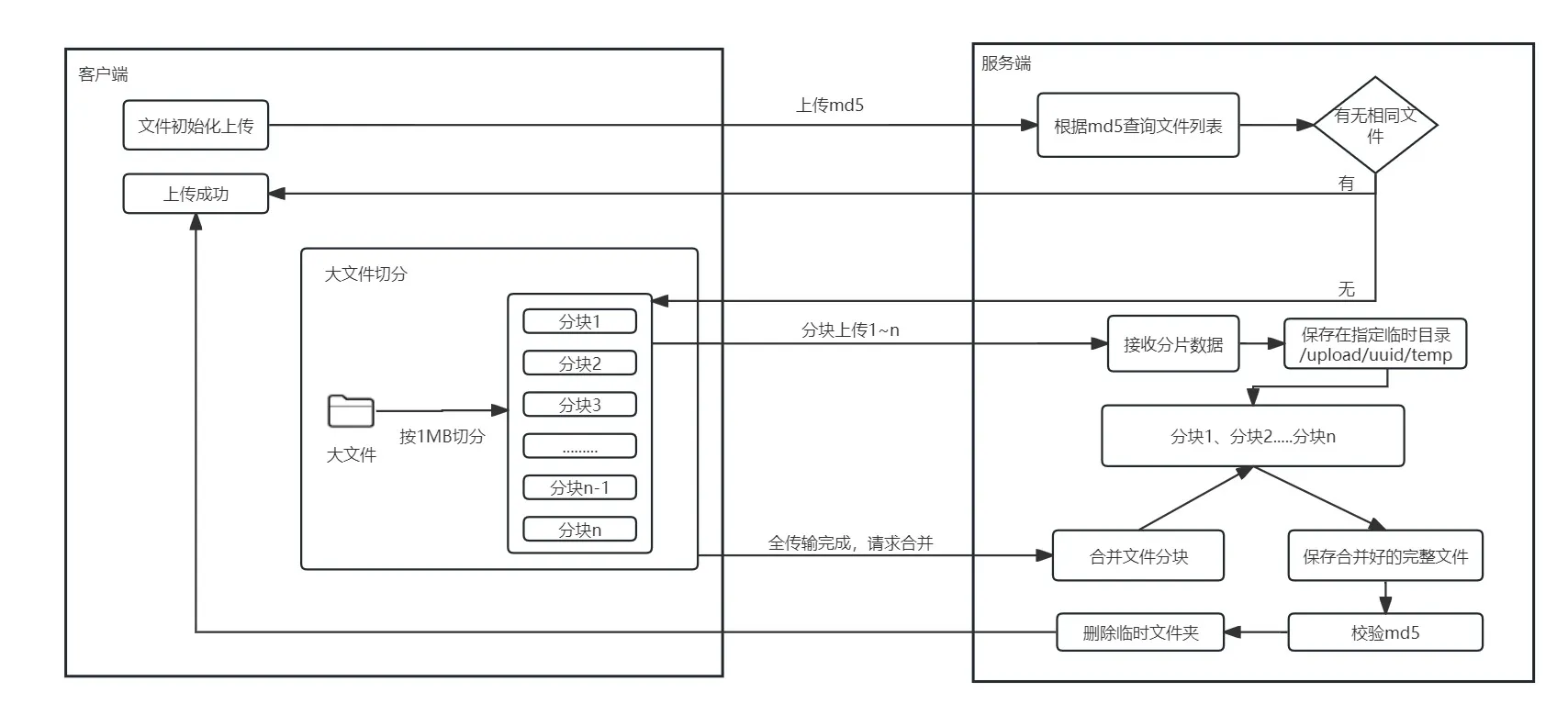
分块上传流程讲解:
- 客户端根据文件大下判断是否需要切片,建议是大于1M的文件,都可以走切片上传。
- 假设文件大小是180MB,那么前端将文件切为180MB/1MB=180个切片,并对这些切片进行编号,0-179。
- 调用上传预准备接口,带上参数:完整文件的md5。
- 服务器根据md5查询文件数据库(mysql或者redis口都可以),检查是否有匹配该md5的文件,有则直接返回上传成功。没有该MD5的文件,生成上传uuid返回给客户端。
- 客户端并发上传这些切片,不要求有序上传。上传切片时,带上参数:当前切片id、上传唯一标识uuid。
- 服务器接收文件分块,把文件内容写入临时目录里,比如 /upload/temp/uuid/,文件名命名为0.uploading, 1.uploading ...
- 客户端的所有切片全部上传成功后,调用服务器的分块合并接口,参数为上传唯一标识uuid、md5、文件名filename、文件分块数。
- 服务器对/upload/temp/uuid/里的按分块id顺序进行读取合并写入到一个新文件,校验合并好的文件MD5是否与客户端上传的md5一致。新文件命名为文件的md5,数据库写一条文件名映射文件路径的记录。
比如:我的视频.mp4 -> /upload/md5
接下来提供一些细节思考和回答,来帮助更深入地理解这个分块上传的技术细节。
Q & A
Q: 什么时候考虑启用文件分块上传,什么时候整个文件上传?
A:这个通过文件大小来决定用哪种上传方式。对于小文件,比如几十KB的文件,那毫无疑问直接整个文件上传。但对于大文件,就选择文件分块上传,至于什么是大文件?每个场景不一样,比如我这边的项目定义1MB以上就是大文件了,此时采用分块上传。
Q: 那对于所谓的大文件,每一个分块切多大比较合适?
A: 这里就考虑切大切小所带来的影响了。
假设文件大小是180MB。
如果分块比较大,前端将文件切为180MB/30MB=6个切片,并对这些切片进行编号,0-5。我们上传这180个分块就要发起http请求6次就可以能完成了,网络额外开销不算很大,但是一旦发生了某一块传输失败,此时重传将会付出更大代价。比如5在传输过程中已经传输了25MB马上就能完成,但是此时用户点了退出,那么该已传输的25MB就会被服务器直接丢失,下次断点续传就要重传这25MB。从用户的角度看来,我在进度90%的时候暂停,下次继续时却从83开始,用户体验不好。尤其是在网络不好的情况下,这个策略并无优势。
如果分块比较小,比如前端将文件切为为180MB/1MB=180个切片,并对这些切片进行编号,0-179。我们上传这180个分块就要发起http请求180次才能完成,从次数而言,网络消耗还是很大的;但是从断点续传来说,正因为分块够小,所以一旦某一个分块传输失败时,重新续传只用传很小一块就好了,从这个角度而言,又确实省了很多网络资源。
总体来说,大文件分块传输更多倾向于把分块切得更小一些比较好,比如1MB。
Q: 文件分多少块这个是由客户端来决定还是服务器来决定?
A: 不重要,都可以。
有些项目前端分好块数,把块数传给服务器存储,这个做法好处是客户端可以自定义自己单个分块的大小,比如web端自定义了单块1MB,而IOS定义单块2MB,比较灵活;
有些是服务器根据客户端上传的文件大小来计算切块数,算好了再发给各个终端来切块,最后上传的块数和服务器算好的块数不一致,那么本次上传就是失败的。这里就直接限制了各个终端的分块逻辑是一致的了,低灵活度保证更多的稳定性。
Q:为什么要传完整文件md5?
A: 用于校验客户端本地的文件与上传来合并好的文件是否完全一致。
Q:怎么标记这些是同一个文件下的分块?
A:初始化上传接口会返回uuid作为本次上传的唯一标识。每一小块上传时,都需要带上这个uuid,那么服务端就知道这个小块归属哪个大文件了。
Q: 如果文件传到一半,用户点了取消,然后重传了一个新文件,但是这个新文件跟之前的文件一样,那进度会从之前的进度继续吗?
A: 不会,从0开始。因为这是一次新的上传,客户端拿到了全新的上传uuid,跟之前所有上传都无关系,此时都是从0开始上传。
Q: 有没有必要每个分块上传时也带上MD5进行校验?
A:没有必要。最后合并成大文件时,做一次MD5校验即可。
Q:上传分块时,是否需要有序上传?
A:不需要,服务器合并分块时,可以根据分块的排序id来有序合并。所以前端切块时需要给分块编号,比如文件切为180MB/1MB=180个切片,那这些切片按顺序进行编号,0-179。上传分块时带上该分块id。
Q: 前端是否可以通过多线程来上传这些分块?
A: 可以,但是要控制并发数。比如180个分片,直接起180个线程来上传,不合适,对客户端对服务端都吃了太多资源来支持上传功能了,合理使用多线程来上传就好,比如4线程,慢慢传。
Q: 假设A和B用户都同时在传同一个文件F,该分块上传流程是否会出问题?
A:没有问题。因为A和B上传时拿到的uuid都是不一样的,因此他们的上传都是独立的流程,存储了自己独自的分块,最后合并会有两份一样的文件存储在服务器上,只是文件路径不一样。
Q: 最后合并分块时能否用多线程写来提速?
A:可以,但需要控制多线程数量,保证不会占用CPU太多资源,另外多线程 合并可能导致短时间读入大量文件进入内存,容易内存爆炸,这里注意读取的方式,一点点地读。
多线程合并思路就是起多线程来读入分块到内存、根据分块排序id计算文件写入偏移量并写入。代码思路如下:
// 分片大小获取
fi, _ := os.Stat("temp/1.uploding")
chunkSize := fi.Size()
// 设置文件写入偏移量
file.Seek(chunkSize*int64(i), 0)
// 在文件偏移位置写入分块数据
len, err := file.Write(fi.data)
如果分块文件特别多时,比如有数千个小文件,此时合并这些小文件将非常耗时。如果想进一步提升合并文件的速度,可以调整下思路,首先我们创建一个合并后的大文件A,并给他设置好大小,文件的大小通过客户端提前告知。我们不单独存储分块文件,而是收到分块文件后,直接找到偏移量和分块大小直接写入文件A,这样就省去后面合并小文件的耗时了。
Q:断点续传怎么做到的?
A:我们都分块上传了,哪些分块还没传,就接着把未上传的分块继续上传就好了。已经上传好分块的都存到服务器了,不用管了。
Q:断点续传可以跨客户端吗?
A:其实是这个场景,用户在电脑A进行文件上传,上传到一半就换了电脑B进行同一份文件上传,此时需要重新上传,不支持断点续传。原因分块上传进度是存在客户端本地的,跨了机器就不知道传到哪个进度了。另外,也不需要考虑跨客户端断点续传,太奇怪了。
Q:可以断点续传,那是否可以断点续载?
A:没问题,跟断点续传原理一样的,首先就是大文件分块,然后一小块一小块地下载,暂停下载后恢复下载,就把未下载的分块继续下载就行,进度是保留的。最后所有分块都下载完后,在客户端进行分块合并就好。
Q:秒传是怎么实现的?
A:换个思路想,如果服务器里已经有我们正准备上传的文件了,是否还要传一次?
秒传的原理很简单,上传前先看看文件是否在之前已经上传过了。这个怎么看?我们每上传一个文件,都记录好其文件MD5以及其存储路径。比如md5为sdadsdjmxkj的文件路径为/upload/test.zip,我们就在数据库mysql插入这么一个数据。当然直接redis存储也行,key为md5,value为存储路径。
每当有文件上传时,先检索下mysql或者redis是否有该md5的文件,有就直接返回上传成功,没有则走正常分块上传流程。