系统的惰性分配和overcommit
2021-05-22
Linux下的内存管理其实都绕不开文章题目的4个词语:缺页、swap、惰性分配和overcommit,而操作系统的内存管理的难点在于:
- 物理内存不够该怎么做?
- 内存分配怎么才能做到高效?
本文想谈的是,内存不足时Linux操作系统是怎么高效分配内存资源的。
Linux 内核给每个进程都提供了一个独立的虚拟地址空间,并且这个地址空间是连续的。这样,进程就可以很方便地访问内存,更确切地说是访问虚拟内存。
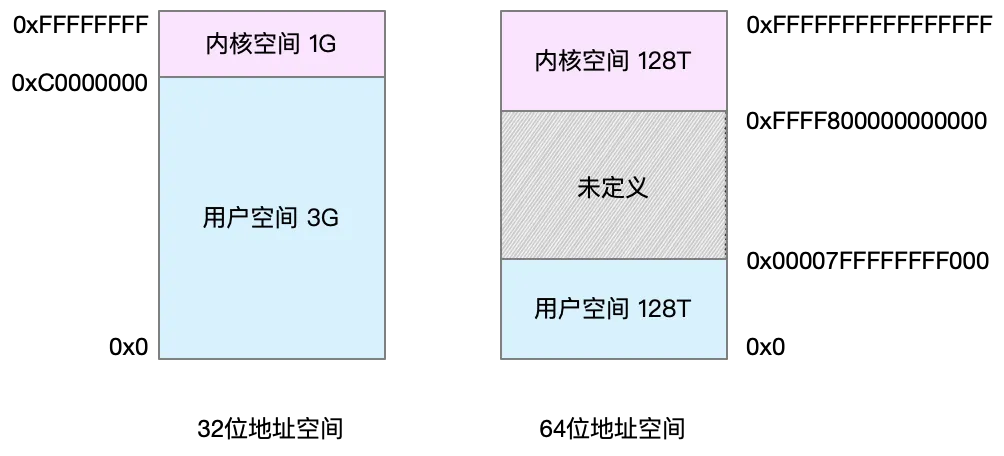
32位操作系统的可寻址范围是4G,因此32位系统的最大可分配的内存空间为4G。比如我们一个32位系统,内存为1G,我们可以给某个进程最大可分配3G内存空间(1G为系统自留使用)。对于64位系统,寻址空间为2的64次方,一个非常大的数,理论上我们不可能使用完这些空间。而64位系统的内核空间和用户空间都是 128T,分别占据整个内存空间的最高和最低处,剩下的中间部分是未定义的。
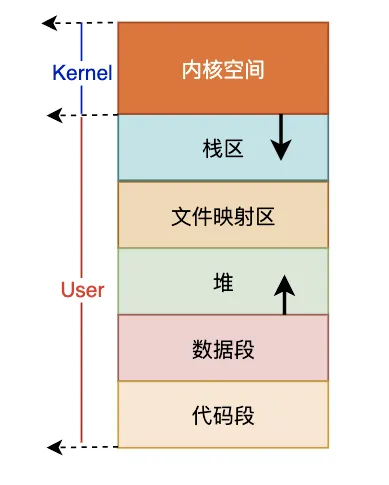
进程是分为内核态和用户态,进程处于用户态时,只能访问用户空间地址,当陷入内核态时,就可以方便地进行系统调用,使用内核空间地址。用户空间内存,从低到高分别是五种不同的内存段。
- 只读段,包括代码和常量等。
- 数据段,包括全局变量等。
- 堆,包括动态分配的内存,从低地址开始向上增长。
- 文件映射段,包括动态库、共享内存等,从高地址开始向下增长。
- 栈,包括局部变量和函数调用的上下文等。栈的大小是固定的,一般是 8 MB。
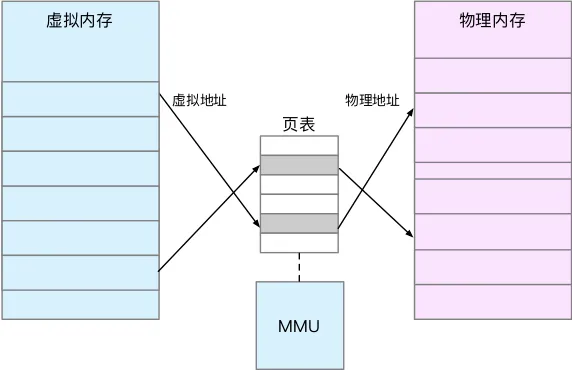
在这五个内存段中,堆和文件映射段的内存是动态分配的。比如说,使用 C 标准库的 malloc() 或者 mmap() ,就可以分别在堆和文件映射段动态分配内存。
因为每个进程都可以寻址的空间范围是虚拟内存的地址大小,如果我们所有进程的虚拟内存加起来,肯定是远比物理内存要大的。操作能做到能向进程提供比物理内存大的虚拟内存,依赖三项技术:
- 快速的内存地址转换(虚拟地址到物理地址)
- 惰性分配
- overcommit
虚拟内存地址映射到物理内存地址,是一项极为高频的操作,CPU并不会直接参与这项转换的工作,而是将地址转换的工作交给了MMU。每个进程都有自己的页表,记录虚拟地址与物理地址的映射关系,大小一般为4KB。页表实际上存储在 CPU 的内存管理单元MMU中,这样,正常情况下,处理器就可以直接通过硬件,找出要访问的内存。
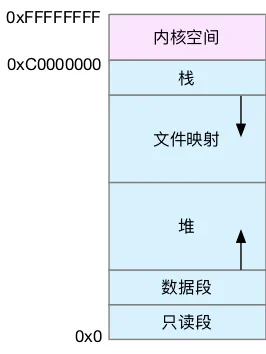
为了加速完成内存映射,操作系统会将TLB(Translation Lookaside Buffer,转译后备缓冲器)作为MMU 中页表的高速缓存,进而提高 CPU 的内存访问性能。当CPU给MMU传新虚拟地址之后,MMU先去问TLB那边有没有,如果有就直接拿到物理地址发到总线给内存,没有则再进行MMU的地址转换操作。
地址翻译的过程:
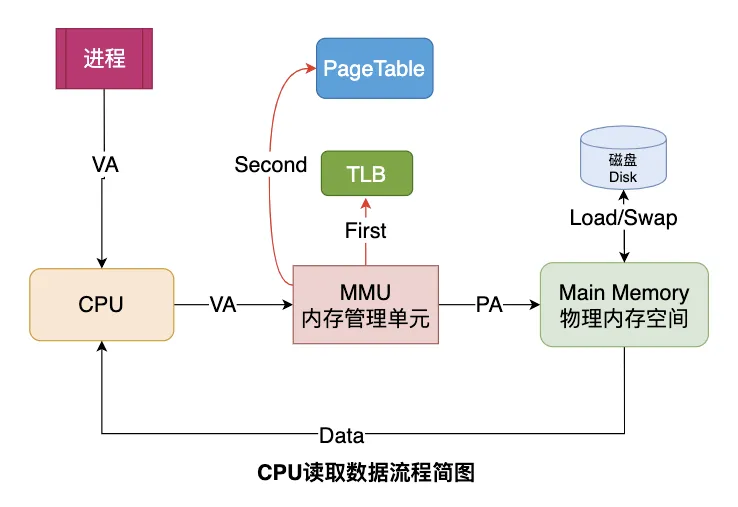
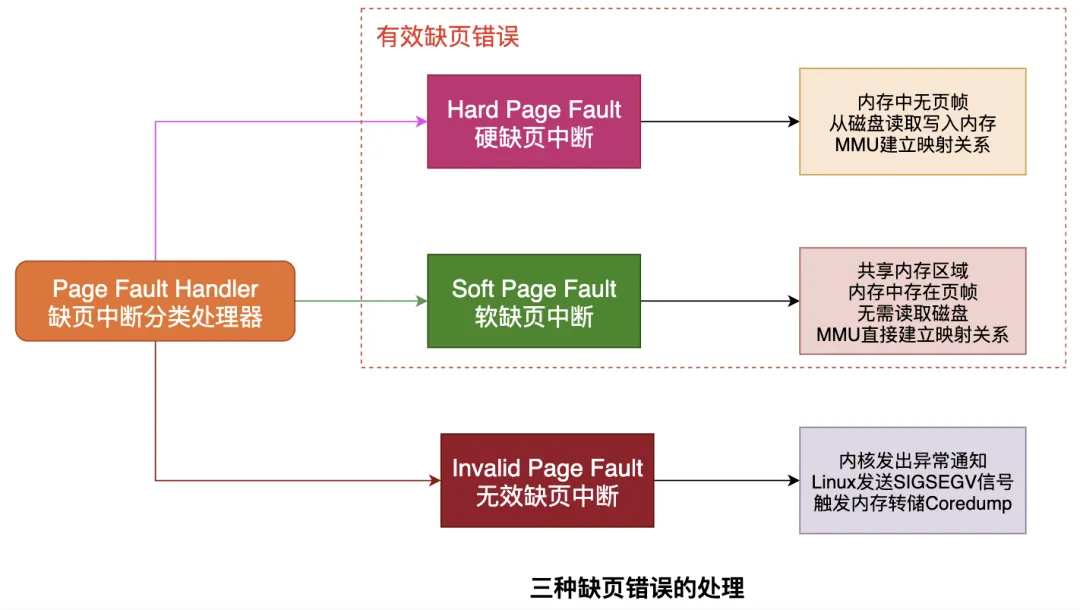
考虑一个问题:虚拟地址在TLB和Page Table都没有找到对应的物理页帧时会发生什么?会发生缺页异常Page Fault,它是一个由硬件中断触发的可以由软件逻辑纠正的错误。假如目标内存页在物理内存中没有对应的页帧或者存在但无对应权限,CPU 就无法获取数据,这种情况下CPU就会报告一个缺页错误。一般的缺页错误有以下三种:
当进程向系统申请分配内存时,操作系统采取的是惰性分配的策略,即系统会快速回应需要内存的进程表示你的申请是有效的,但此时并不会为该进程真正分配出内存空间,而是在该进程真正使用到这段内存时才真正分配,这就是惰性分配思想。操作系统采取惰性分配的好处个人认为如下:
避免某些进程空占着内存资源。有些进程在初始化时就先分配了大量内存,但这些内存空间也许要等到某些条件触发时才会利用上,也有可能到进程退出时也用不到这些内存,因此为了保证内存的使用率,惰性分配很有必要。以一个“延时满足”的思想解决了内存消耗过快的问题。
我们知道,物理内存不足我们可以通过swap分区来扩展可利用的内存资源,也就是虚拟内存。
虚拟内存在逻辑上是很大,但是实际上我们不会无节制地开启虚拟内存,一般而言,我们线上的服务器都是采取物理内存+swap分区的策略,比如8G的物理内存+8G swap分区的策略,比较高效的处理内存不足的问题。swap的思想是把不常用的内存数据放在磁盘中去,Swap 其实就是把一块磁盘空间当成内存来用。它可以把进程暂时不用的数据存储到磁盘中(这个过程称为换出,swapout),当进程访问这些内存时,再从磁盘读取这些数据到内存中(这个过程称为换入,swapin),那怎么判定内存的哪些数据是不常用数据需要换出呢,LRU,LFU等都是常用的算法。当物理内存紧张的情况下,当进程访自己已申请的内存地址时,操作系统发现这段内存地址并不在物理内存里,此时就会发生缺页中断,根据内存置换算法选出指定页swapout到磁盘,再将马上要使用到的页swapin到内存,完成了页面的swapin和swapout。
那当我们不得不开启swap时,swap分区的大小该怎么设计呢?一般而言,内存和swap分区的大小1:1是个不会太错的选择,比如4G的物理内存可以考虑配备4G的swap分区。如果物理内存远小于swap分区大小会有什么后果?这样的配备首先说明物理内存已经远不能处理进程的数据了,需要通过大量借助磁盘来扩展内存才能满足进程需求。这本来就是一个不合理的配比,这会导致内存数据块频繁地被置换到磁盘,产生大量的磁盘IO,导致系统很卡(系统性能都全消耗在缺页中断产生的磁盘IO),上面跑的进程很难得到有效调度。
但反过来,物理内存远大于swap分区并无副作用,比如我们线上 的服务器,物理内存256G,平时活动高峰期内存也完全足够,但为了稳妥起见,我们也还是配了16G的swap分区,作为系统内存异常时的一个最后保障。一些线上服务为了保持高性能一般都会把swap关掉,比如redis。
这是我们线上服务器的物理内存和交换分区的配比情况,128G物理内存 + 4G的交换分区,因为游戏服务器非常重视单机高性能,所以基本都是内存能开多大就开多大,swap的开启也只是为了某些极端情况下的保底处理,正常情况下都用不上。
Mem: 14G Active, 21G Inact, 43G Wired, 1239M Buf, 47G Free
Swap: 4096M Total, 4096M Free
我们回到讨论内存分配机制。惰性分配会引入一个新问题:开空头支票带来的副作用,当进程真正要使用早期申请的这块内存时,系统发现系统的总的可利用的内存(物理内存+swap)已经用完了,没法兑现早期的承诺了,这就是操作系统的overcommit。这里继续举个例子来说明:
系统总可利用的内存资源总大小时4G,一个进程在初始化时向系统申请1G资源,系统因为惰性分配的原因,只回复了该进程已为你分配了1G资源,但实际上幷没有开始分配。一段时间后,该进程需要访问这段已申请的内存地址,系统开始马上回顾当前剩余的空间,发现可用的内存空间已不足200M,此时就是overcommit,翻译过来就是“过度承诺”,操作系统这种操作之后,需要一些措施来收拾残局。
针对overcommit的场景,首先想到的是,为什么不可以在进程向系统申请分配空间时,系统先去查一下已分配出多少内存空间了,然后再决定是否回复进程本次申请是否成功?答案是可以的,Linux对应的是系统的一个配置,直接禁用overcommit就好。但是禁用的坏处是,内存的利用率不高。考虑到进程之间很少会同时访问大量内存空间,比如4G的内存,操作系统进行overcommit了12G的的空头支票给进程,因为并不是所有进程都在同一刻要求使用4G以上的内存资源,所以overcommit在大多数场合是合适的,不开启overcommit,可利用的资源是4G,开启后可能就可以达到8G甚至更多。但最后还是得有措施保底,即真的有某一个时刻进程要使用的内存空间大于可利用的内存空间呢?
上面的swap是为了解决物理内存不足,但当物理内存+交换分区都不足时,比如上面的配置,我们可以利用的虚拟内存总和就是16G,当已分配的内存超过这个数字时,操作系统必须采取某个策略来处理内存不足的问题了。事实上,内存再大,对应用程序来说,也有不够用的时候。
这个策略就是OOM killer,即当系统中可利用的内存资源已经耗尽时,OOM killer机制会对杀死分数最高的进程,以求释放内存资源保证系统可以稳定运行。
在Linux上swap,overcommit都是有参数可以调整的,比如调overcommit对应的参数是overcommit_memory。
overcommit_memory是一个内核对内存分配的一种策略,它有三个可选值:0、1、2。
https://github.com/torvalds/linux/blob/master/include/uapi/linux/mman.h
#define OVERCOMMIT_GUESS 0
#define OVERCOMMIT_ALWAYS 1
#define OVERCOMMIT_NEVER 2
- 0:内核将检查是否有足够的内存分配给程序。如果没有则申请失败,并把错误返回给应用进程。而在Redis中这个错误就会表现为“Cannot allocate memory”,然后触发OOM
- 1:表示内核允许超量使用内存直到用完为止
- 2:表示内核决不超量使用内存,即系统整个内存空间不能超过swap+50%的RAM值,50%是overcommit_ratio默认值,此参数支持修改
lijunshi@GIH-D-21171:/mnt/e/services$ grep -i commit /proc/meminfo
CommitLimit: 515524 kB
Committed_AS: 3450064 kB
其中, CommitLimit = swap(交换内存) + mem(物理内存) * overcommit_ratio / 100。这和CommitLimit的数值是吻合的。
overcommit_ratio查看方法如下:
$ cat /proc/sys/vm/overcommit_ratio
50
所以我们可以根据需求配置这个参数,刚举的例子就是对应为参数1,允许内核分配超过所有物理内存和交换空间总和的内存,当实在是无法处理时就使用OOM killer杀进程释放内存。在实际案例中,Redis建议把这个值设置为1,是为了让bgsave时fork能够在低内存下也执行成功。
这是我个人PC上的ubuntu的内存配置,16G物理内存搭配了48G的swap分区,物理内存已消耗了50%,但此状态下的swap很低,基本没有使用。
lijunshi@GIH-D-21171:/mnt/e/services$ free -h
total used free shared buff/cache available
Mem: 15Gi 7.3Gi 8.4Gi 17Mi 223Mi 8.5Gi
Swap: 48Gi 124Mi 47Gi
lijunshi@GIH-D-21171:/mnt/e/services$ cat /proc/sys/vm/overcommit_memory
0
lijunshi@GIH-D-21171:/mnt/e/services$ cat /proc/sys/vm/swappiness
60
我的ubuntu系统overcommit_memory默认为0,即表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。也就是每次内存申请时都将判定这次申请是否真的成功,放弃惰性分配策略,不会产生overcommit现象。
而swap分区对应的内存参数是swappiness。swappiness的值的大小对如何使用swap分区是有着很大的联系的。swappiness=0的时候表示最大限度使用物理内存,然后才是swap空间,swappiness=100的时候表示积极的使用swap分区,并且把内存上的数据及时的搬运到swap空间里面。linux的基本默认设置为60。当swappines设置得比较大时,你会发现即使系统物理内存还剩余很多,但系统还是倾向于大量使用很慢的swap分区,这就导致系统很卡。但值得注意的是swappiness=0并不表示禁用交换分区,而是指尽可能不使用交换分区,但当内存已经耗尽时也会选择使用交换分区,如果不想使用交换分区,那就不要启用swap。
所以一个重要的性能优化经验就是:最好禁用swap。swap应该是针对以前内存小的一种优化,如果是高性能服务,最好禁止 Swap,比如redis,mysql等服务,都是推荐禁用swap的。如果必须开启 Swap,那需要降低 swappiness 的值,减少内存回收时 Swap 的使用倾向。